基本数据结构
栈和队列
栈
后进先出
S.top指向最新插入的元素
- S.top=0:栈为空


队列
先进先出
Q.head指向队头元素,Q.tail指向下一个新元素将插入的位置
Q.head=Q.tail时:队列为空
初始时:Q.head=Q.tail=1
Q.head=Q.tail+1时:队满

1 | // LeetCode 622:实现循环队列 |
1 | // LeetCode 641:实现循环双端队列 |
链表
搜索:$O(n)$
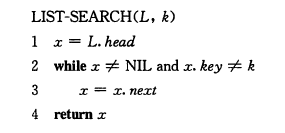
插入:$O(1)$

删除:$O(1)$

哨兵
1 | // LeetCode 707. 设计链表 |
1 | //LeetCode 206 反转链表: |
有根树
- 二叉树
- 多叉树
- 左孩子右兄弟表示法
散列表
- 实现字典操作的一种有效数据结构
- 关键字为$k$的元素放置在槽$h(k)$中
- 装载因子:对能存放$n$个元素,$m$个槽位的散列表$T$,$T$的装载因子定义为$\alpha=n/m$
冲突解决方法1:链接法
把散列到同一个槽中的所有元素都放在一个链表中

插入操作最坏运行时间:$O(1)$
删除操作:$O(1)$(直接删除,双向链表)
查找操作:最坏$O(n)$(所有关键字映射到同一个槽)
- 平均性能依赖于散列函数
- 简单均匀散列
- 一次成功/不成功查找的平均时间都为$\Theta(1+\alpha)$
- 则所有操作都能在$O(1)$时间内完成
散列函数
- 除法散列法
- 乘法散列法
- 全域散列法
1 | // LeetCode 705: 设计哈希集合 |
1 | // LeetCode 706: 设计哈希映射 |
冲突解决方法2:开放寻址法
散列表可能会被填满,装载因子$\alpha$不能超过1


删除操作比较困难:用特定值DELETED代替NIL来标记
- 一般需要删除时还是用链接法更好
探查序列的方法
- 必须保证探查序列是<0,1,...,m-1>的一个排列
- 均匀散列假设:每个关键字的探查序列等可能地为<0,1,...,m-1>的m!种排列中的任一种
- 插入:至多$1/(1-\alpha)$次探查
- 不成功查找:至多$1/(1-\alpha)$次探查
- 成功查找:$\frac { 1 } { \alpha } \ln \frac { 1 } { 1 - \alpha }$
- 三种探查技术
- 线性探查:$h ( k , i ) = ( h ^ { \prime } ( k ) + i ) \bmod m, i = 0,1 ,\cdots m - 1$
- m种不同的探查序列
- 二次探查:$h ( k , i ) = ( h ^ { \prime } ( k ) + c _ { 1 } i + c _ { 2 } i ^ { 2 } ) \bmod m$
- 双重探查:$h ( k , i ) = ( h _ { 1 } ( k ) + i h _ { 2 } ( k ) ) \bmod m$
- 线性探查:$h ( k , i ) = ( h ^ { \prime } ( k ) + i ) \bmod m, i = 0,1 ,\cdots m - 1$
完全散列
最坏情况$O(1)$
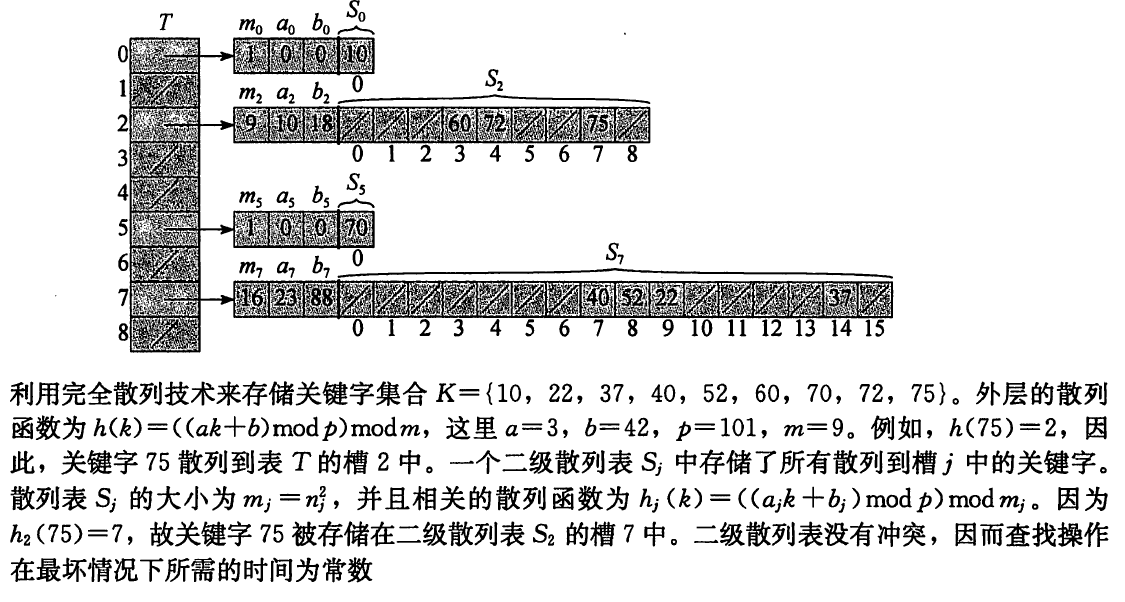
- 二级散列表,需要确保第二级散列表不发生冲突(略)
二叉搜索树
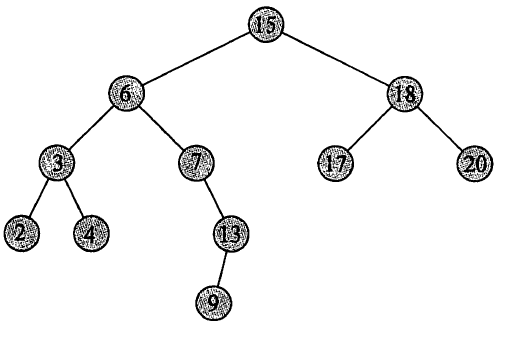
设 x 是二叉搜索树中的一个结点。
- 如果 y 是 x 左子树中的一个结点,那么 y.key ≤x.key 。
- 如果 y 是 x 右子树中的一个结点,那么 y.key ≥ x.key 。
遍历二叉树($\Theta (n)$)
中序遍历

先序遍历
后序遍历
查询
查询(O(h))
- 递归写法:

1
2
3
4
5
6
7
8
9
10
11
12
13// 700 二叉搜索树中的搜索
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if(!root)
return nullptr;
if(root -> val == val)
return root;
if(root -> val > val)
return searchBST(root -> left, val);
return searchBST(root -> right, val);
}
};
迭代写法:

最大、最小元素(O(h))
前驱和后继(O(h))
- 分两种情况:
若结点x的右子树非空,那么x的后继是x右子树中的最左节点
若结点x的右子树为空,向上遍历直到遇到一个祖先节点,它是其父结点的左孩子,返回父结点的值

- 分两种情况:
插入
- 先搜索,直到nil,然后将nil替换为新节点($O(h)$)

1 | // leetcode 701:二叉搜索树中的插入操作 |
删除
四种情况
- z没有孩子结点:直接删除
- z只有一个孩子:将孩子提升到z的位置
- z有两个孩子:查找z的后继y(右子树种寻找中序下的第一个节点)
- y就是z的右孩子:y直接替换z
- y位于z的右子树但不是z的右孩子:先用y的右孩子替换y,然后用y替换z
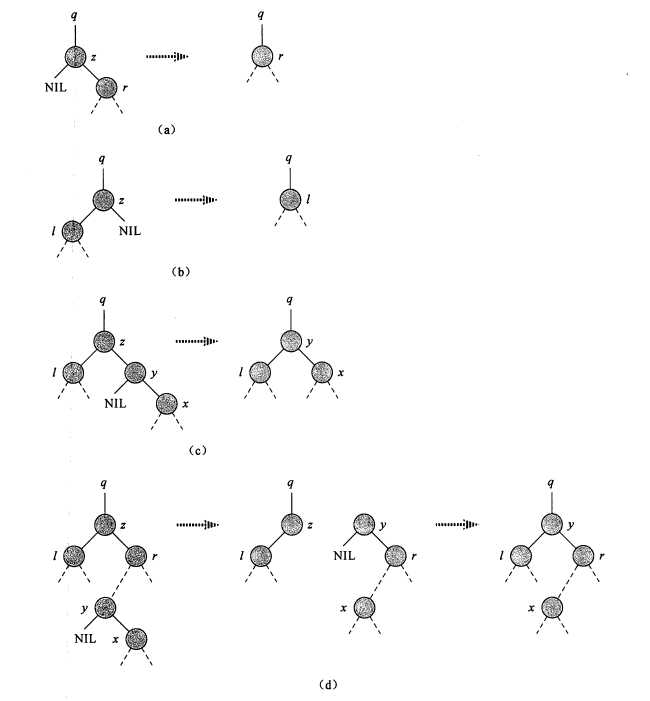
实现
用子树v替换u

删除($O(h)$)

1 | //leetcode 450: 删除二叉搜索树中的节点 |
随机构建二叉搜索树
- 如果n个关键字按严格递增的顺序被插入,则这棵树一定是高度为n-1的一条链
- 随机顺序插入:性能较好
红黑树
平衡搜索树中的一种,可以保证在最坏情况下基本动态集合操作的时间复杂度为$O(lgn)$
一棵红黑树是满足下面红黑性质的二叉搜索树 :
1 . 每个结点或是红色的 , 或是黑色的 .
2 . 根结点是黑色的 .
3 . 每个叶结点 ( NIL ) 是黑色的 .
4 . 如果一个结点是红色的 , 则它的两个子结点都是黑色的 .
5 . 对每个结点 , 从该结点到其所有后代叶结点的简单路径上 , 均包含相同数目的黑色结点 .
数据结构的扩张
顺序统计树
每个节点增加一个信息:x.size
- 根为x的子树的结点数
查找根为x、秩为i(第i小)的结点

确定一个元素的秩(P194)
- 遍历祖先节点,遇到是右子树的情况,加上左边所有节点的个数

维护子树规模
- 插入时每个父结点size+1
区间树
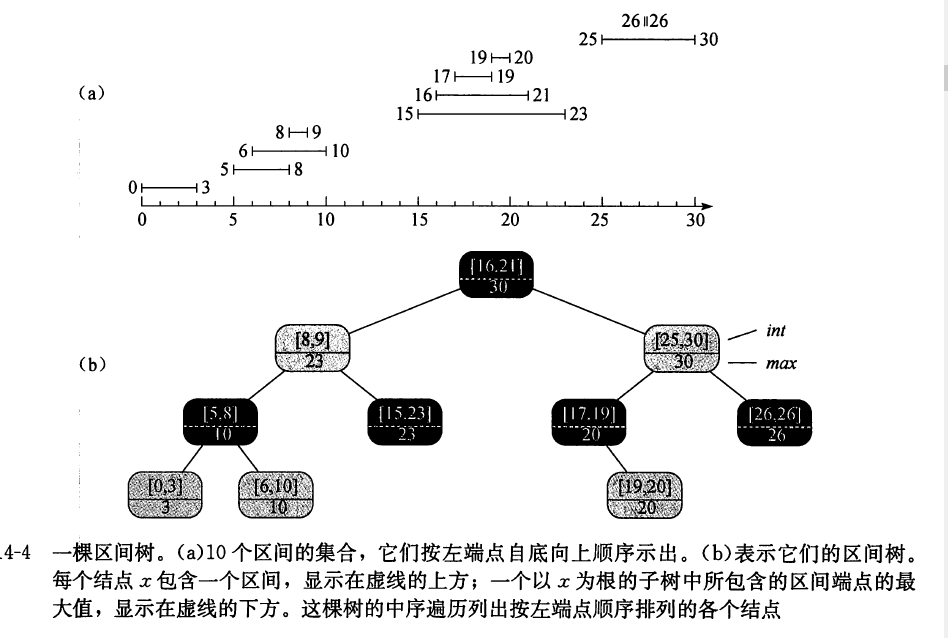
搜索与区间i有重叠的区间:

并查集
维护一个不相交动态集的集合$S$,用一个代表来标识每个集合。
操作
- MAKE_SET(x):建立一个新的集合,唯一成员是x
- UNION(x,y):合并包含x和y的两个集合
- FIND-SET(x):返回包含x的唯一集合的代表
链表表示
- MAKE_SET和FIND_SET:O(1)
- UNION:与合并的链表长度呈线性关系
- 启发式策略:总是把较短的表拼接到较长的表上
- 总开销:$O(m+nlgn)$

有根树表示

启发式策略
按秩合并:对每个节点,维护一个秩,它表示该结点高度的一个上界,让具有较小的秩的根指向具有较大秩的根
路径压缩:FIND-SET时让查找路径中的每个结点直接指向根

运行时间:$O(m\alpha(n))$,其中$\alpha(n) < 4$
- m:总操作次数
- n:结点数
1 | // 并查集的C++实现 |
Trie字典树
由于一个英文单词的长度n 通常在10以内,如果我们使用字典树,则可以在O(n)时间内完成搜索,且额外开销非常小。
插入
时间复杂度:O(m),其中 m 为键长。在算法的每次迭代中,我们要么检查要么创建一个节点,直到到达键尾。只需要 m 次操作。
空间复杂度:O(m)。最坏的情况下,新插入的键和 Trie 树中已有的键没有公共前缀。此时需要添加 m 个结点,使用 O(m) 空间。
查找
- 时间复杂度 : O(m)。算法的每一步均搜索下一个键字符。最坏的情况下需要 m 次操作。
- 空间复杂度 : O(1)。
1 | // LeetCode 208. 实现 Trie (前缀树) |
线段树
线段树是算法竞赛中常用的用来维护 区间信息 的数据结构。
线段树可以在$O(logN)$的时间复杂度内实现单点修改、区间修改、区间查询(区间求和,求区间最大值,求区间最小值)等操作。
建树 :数组空间4N
1 | // LeetCode 307. 区域和检索 - 数组可修改 |